




I. Qu'est-ce que le Mapping Objet/Relationnel▲
Un logiciel de Mapping Objet / Relationnel est une couche de persistance connectant les objets d'un système orienté objet à des données stockées dans une base de données relationnelle.
Pour simplifier, vous pouvez vous dire que le Mapping Objet/Relationnel consiste à modéliser, de façon objet, une base de données. Ainsi, les tables de la base de données deviennent des classes, avec une liste de propriétés qui correspondent aux colonnes de la table.
Une couche de persistance, c'est en quelque sorte une surcouche à votre projet, qui se chargera de représenter vos tables en classes.
C'est grâce à cette couche de persistance que vous allez pouvoir appeler des méthodes de votre classe, qui seront en fait des méthodes agissant directement sur votre base de données (méthodes Save, Update, etc.).
Vous avez donc la possibilité de créer cette couche de persistance vous-même : pour chaque table de la base de données, vous créez la classe associée (en prenant garde de bien respecter les clés primaires, les identifiants autogénérés, etc..). Ce travail n'est pas impossible, mais long et fastidieux.
Ou bien vous pouvez utiliser un logiciel qui créera pour vous, automatiquement, cette couche de persistance (cas le plus courant).
II. Pourquoi le Mapping Objet/Relationnel▲
Vous pouvez vous demander quel est l'intérêt du Mapping Objet/Relationnel ?
Si vous voulez faire abstraction de toute la partie SQL, et ne travailler qu'avec des objets (à proprement parler), le Mapping O/R est fait pour vous.
Une autre possibilité, du Mapping O/R, qui pourra vous séduire : si vous voulez mettre à jour, de façon complètement automatique, votre base de données, vous n'avez qu'à appeler une méthode Update (ou Save) sur l'un de vos objets. Grâce au Maping, la connexion à la base de données, les requêtes SQL et la fermeture de la connexion seront effectuées sans que vous ayez besoin d'écrire une seule ligne de SQL !
Cependant, prenez garde : le Mapping Object/Relationnel est tout de même critiquable d'un certain point de vue. En effet, en Programmation Orientée Object (POO), un objet n'est pas toujours représenté par une table d'une base de données : le Mapping O/R n'est donc pas une solution miracle.
Cet article a pour vocation de vous donner un aperçu des possibilités du logiciel Persistent Dataset.
III. Le Mapping Objet/Relationnel avec Persistent Dataset▲
Après avoir terminé l'installation du logiciel, rien ne semble, à priori, avoir changé dans votre Visual Studio. Commencez par vérifier que l'addin est bien chargé.
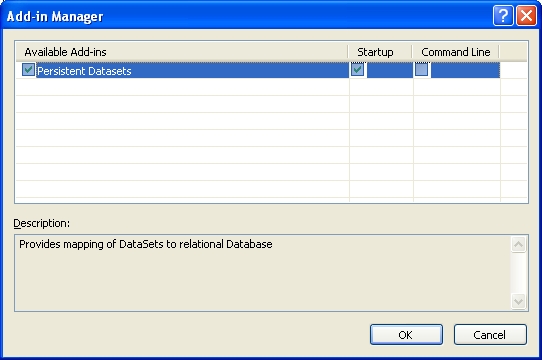
Pour cela, cliquez sur le menu « Tools », puis « Add-ins Manager », et là, vérifiez que Persistent Datasets est bien sélectionné :
Affichez maintenant la barre d'outils de Persistent Datasets : faites un clic droit sur la barre à outils de Visual Studio et choisissez « Persistent Datasets » :

Maintenant que l'installation est terminée et que vous avez fini le paramétrage de Visual Studio, voyons comment utiliser les fonctionnalités du produit.
III-A. Avantages de Persistent Datasets▲
Persistent Datasets possède de nombreux avantages. Je ne vais pas vous en faire la liste détaillée, mais notez ceux-ci qui sont, pour moi, les plus importants :
- support des Generics (.NET 2.0) ;
- support des types Nullable ;
- les résultats d'une requête peuvent être récupérés directement depuis la base de données, ou bien stockés dans des Dataset fortement typés ;
- persistent Datasets utilise la même syntaxe que DLINQ (Data Language Integrated Queries). Voir ici pour plus d'informations sur DLINQ.
III-B. Ajout de la couche de persistance▲
Faîtes un clic droit que le nom de votre projet, choisissez « Add » => « New Item » et sélectionnez « Persistent Layer » :

C'est à cet endroit-là que vous allez pouvoir générer votre couche de persistance, ainsi que tous les objets du domaine, etc.
« Mapping Schema » vous permettra de paramétrer la chaine de connexion à la base de données, et de spécifier des conventions de nommage :

Positionnez-vous alors sur « DB Objects » puis cliquez sur « Add » pour ajouter les tables de la base de données sur lesquelles vous souhaitez travailler :
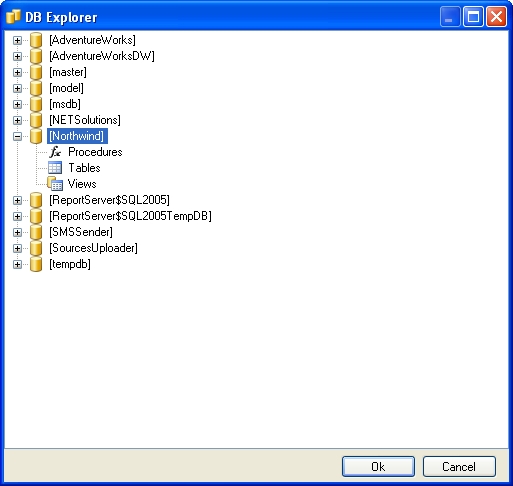
Une fois les tables ajoutées, vous pouvez utiliser le propertyGrid situé sur la droite pour modifier les paramètres de génération d'une ou plusieurs tables.
« Typed Objects » vous permettra également de modifier certaines options, telles que les conventions de nommage des objets du domaine, des objets d'accès aux données, etc.
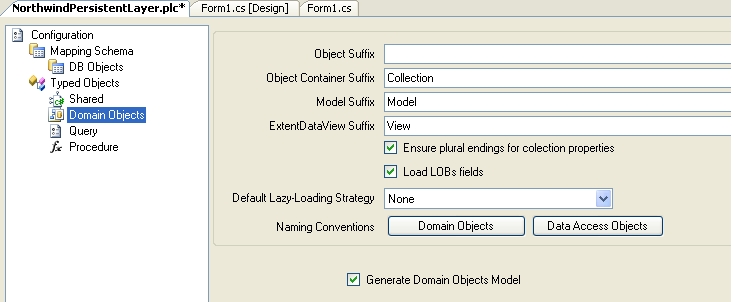
Cliquez alors sur « Generate Persistent Layer » pour générer votre couche de persistance et voir les objets du domaine (et autres classes importantes) se générer automatiquement :
La liste des fichiers composant votre couche de persistance est ajoutée à votre projet :

III-C. Génération du Framework d'initialisation▲
Maintenant que votre couche de persistance est générée, il va vous falloir créer le framework qui servira à activer la persistance. Pour cela, rien de plus simple : dans votre code, placez ce bout de code :
//Instructs framework to ativate persistentce for mapping schema
MappingSchemaFactory.Add(Assembly.GetExecutingAssembly(), Assembly.GetExecutingAssembly(),
"ClientApp.NorthwindPersistentLayer.xsd");
//Initialize Default DataBroker.
// Votre chaine de connexion
string connectionString = @"Data Source=.\SQL2005; Initial Catalog=Northwind;User Id=sa; Password=";
DataBroker.DefaultDataBroker = new DataBroker(new SqlDataProvider(), connectionString, null);
//Enable SQL Trace
DataBroker.DefaultDataBroker.EnableTraceSql = true;
Il y a trois choses que vous allez devoir changer pour que votre code soit correct :
- le nom du Dataset : ClientApp.NorthwindPersistentLayer.xsd est le nom du Dataset généré par la couche de persistance. Vous allez devoir le remplacer par le nom de votre Dataset (en effet, NorthwindPersistentLayer n'est sans doute pas le nom que vous avez donné à votre couche de persistance). Attention, ce nom est composé de la sorte : namespace.nom_du_dataset.xsd ;
- la chaine de connexion : en effet, c'est à vous d'adapter la chaine de connexion de votre code ;
- le provider SQL à utiliser : si vous utilisez une base de données Oracle, vous allez devoir remplacer SqlDataProvider par OracleDataProvider.
Pensez également à rajouter les clauses « using » (ou « Import », si vous faites du VB.NET) nécessaires :
using LastComponent.PersistentDataSets.Framework;
using LastComponent.PersistentDataSets.Framework.Data.SqlServer;
using LastComponent.PersistentDataSets.Framework.Schema;
Une fois que cela est fait, voyons les différentes opérations qu'il nous est possible de réaliser sur la base de données.
III-D. Sélection de données▲
Une fois que vous êtes arrivé jusque là, Visual Studio 2005 vous a généré un composant, le modèle de la couche de persistance. Comme tous les composants, celui-ci ce trouve dans la boîte à outils, et il ne vous reste plus qu'à le glisser/déposer pour pouvoir l'utiliser dans votre projet :
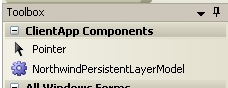
C'est grâce à ce modèle que vous allez pouvoir avoir accès à votre base de données.
En effet, si vous voulez faire un simple SELECT de la table Customers de votre base de données, rien de plus simple : il vous suffit d'utiliser les classes de type XXXQuery, où XXX représente la table que vous souhaitez interroger. Voici un exemple :
CustomerQuery listClients = new CustomerQuery();
Ce bout de code me sert à récupérer toutes les lignes de la table Customers. Voici d'ailleurs la requête SQL exécutée pour récupérer cette liste (cette requête est visible grâce au paramètre EnableTraceSql = true, que vous avez mis lors de l'initialisation du framework) :
SELECT A0.[CustomerID], A0.[CompanyName], A0.[ContactName], A0.[ContactTitle], A0.[Address], A0.[City], A0.[Region],
A0.[PostalCode], A0.[Country], A0.[Phone], A0.[Fax]
FROM [Northwind].[dbo].[Customers] A0
Avec une ligne de code, vous avez réussi à écrire l'équivalent d'une ligne de SQL, sans pour autant connaitre le SQL ! Magique non :)
Maintenant que vous avez ce jeu de résultat, il faut bien en faire quelque chose. Dans notre cas, nous allons nous en servir pour alimenter une GridView.
Pour cela, il vous faut appeler la méthode Fill de la table, du modèle de données, que vous voulez remplir. Concrètement, voici comment cela se caractérise, par le code :
// Requête sur la table Customers
CustomerQuery listClients = new CustomerQuery();
// Remplissage de la table Customers du modèle de données
northwind.Customers.Fill(listClients);
Et c'est terminé ! Il ne vous reste plus qu'à associer la propriété northwind.Customers à la propriété DataSource de votre DataGridView, et à observer le résultat :
cbClientList.DataSource = northwind.Customers;
Ce qui donne en image :

Simple non ?! Voici le code source complet de cet exemple :
using (TransactionContext ts = new TransactionContext(TransactionOption.Required))
{
// Requête sur la table Customers
CustomerQuery listClients = new CustomerQuery();
// Remplissage de la table Customers du modèle de données
northwind.Customers.Fill(listClients);
cbClientList.DataSource = northwind.Customers;
cbClientList.DisplayMember = northwind.Customers.ContactName.SourceColumn;
cbClientList.ValueMember = northwind.Customers.CustomerID.SourceColumn;
}Une chose importante à savoir et à garder à l'esprit : À chaque fois que vous faites un accès à votre base de données, vous devez utiliser une transaction, afin de prévenir toute erreur. C'est pourquoi le code précédent est inclus dans la directive using suivante : TransactionContext ts = new TransactionContext(TransactionOption.Required)
III-E. Sélection de données avec critères▲
Une autre possibilité de Persistent Datasets : faire une sélection de données, en utilisant des critères de choix. Voici un exemple, où on ne demande que la liste des Customers, dont le ContactName contient la lettre A :
using (new TransactionContext(TransactionOption.Required))
{
// On interroge la table Customers
CustomerQuery listClients = new CustomerQuery();
// On en sélectionne que ceux dont le ContactName contient la lettre A
listClients.Criteria = listClients.ContactName.Like("%A%");
northwind.Customers.Fill(listClients);
cbClientList.DataSource = northwind.Customers;
cbClientList.DisplayMember = northwind.Customers.ContactName.SourceColumn;
cbClientList.ValueMember = northwind.Customers.CustomerID.SourceColumn;
}
Voici d'ailleurs la requête SQL correspondante à ce code :
SELECT A0.[CustomerID], A0.[CompanyName], A0.[ContactName], A0.[ContactTitle], A0.[Address], A0.[City], A0.[Region],
A0.[PostalCode], A0.[Country], A0.[Phone], A0.[Fax]
FROM [Northwind].[dbo].[Customers] A0
WHERE (A0.[ContactName] LIKE '%A%')III-F. Sélection de données avec critères multiples▲
Bien sûr, vous pouvez tout à fait multiplier les critères de sélection ! Voici d'ailleurs un exemple :
using (new TransactionContext(TransactionOption.Required))
{
// On interroge la table Customers
CustomerQuery listClients = new CustomerQuery();
// On en sélectionne que ceux dont le ContactName contient la lettre A
listClients.Criteria = listClients.ContactName.Like("%A%") &&
listClients.Orders.OrderDate.Between(new DateTime(1982, 06, 28), DateTime.Now);
northwind.Customers.Fill(listClients);
cbClientList.DataSource = northwind.Customers;
cbClientList.DisplayMember = northwind.Customers.ContactName.SourceColumn;
cbClientList.ValueMember = northwind.Customers.CustomerID.SourceColumn;
}
Et la requête SQL générée :
SELECT A0.[CustomerID], A0.[CompanyName], A0.[ContactName], A0.[ContactTitle], A0.[Address], A0.[City], A0.[Region],
A0.[PostalCode], A0.[Country], A0.[Phone], A0.[Fax]
FROM [Northwind].[dbo].[Customers] A0
INNER JOIN [Northwind].[dbo].[Orders] A1 ON (A0.[CustomerID] = A1.[CustomerID])
WHERE ((A0.[ContactName] LIKE '%A%') AND (A1.[OrderDate] BETWEEN '28/06/1982' AND '11/02/2006'))
On se rend tout de suite compte que cette requête SQL est plus complexe que les autres et pourtant, le code qui l'a généré est on ne peut plus simple à écrire et comprendre !
On appréciera surtout, dans le cas de la sélection de données avec des critères multiples, la syntaxe du code très particulière (mais agréable) inspirée de LINQ.
III-G. Sélection de données avec clauses (ORDER BY, GROUP BY, etc…)▲
Si vous avez besoin de faire une requête SQL avec une clause (type ORDER BY; GROUP BY, etc.), sachez que Persistent Datasets vous permet de le faire toujours très simplement.
Voyons cela en exemple :
using (new TransactionContext(TransactionOption.Required))
{
// On interroge la table Customers
CustomerQuery listClients = new CustomerQuery();
// On en sélectionne que ceux dont le ContactName contient la lettre A
listClients.Criteria = listClients.ContactName.Like("%A%");
listClients.OrderByList.Add(listClients.ContactName, true);
northwind.Customers.Fill(listClients);
cbClientList.DataSource = northwind.Customers;
cbClientList.DisplayMember = northwind.Customers.ContactName.SourceColumn;
cbClientList.ValueMember = northwind.Customers.CustomerID.SourceColumn;
}
Ici, on voit bien que la ligne : listClients.OrderByList.Add(listClients.ContactName, true); a été ajoutée et on devine facilement qu'elle nous sert à ajouter une clause de type ORDER BY.
OrderByList est en effet une collection de clause ORDER BY : on se contente donc d'ajouter, à cette collection, un élément. Dans l'exemple ci-dessus, j'ai trié par nom, et dans l'ordre alphabétique, le jeu de résultat retourné par ma requête.
Le résultat en image :

Là encore, une requête SQL est générée :
SELECT A0.[CustomerID], A0.[CompanyName], A0.[ContactName], A0.[ContactTitle], A0.[Address], A0.[City], A0.[Region],
A0.[PostalCode], A0.[Country], A0.[Phone], A0.[Fax]
FROM [Northwind].[dbo].[Customers] A0
ORDER BY A0.[ContactName] ASC
Je ne vous montrerais que cet exemple, mais sachez que toutes les autres clauses SQL sont réalisables.
III-H. Sélection d'une ligne de la base de données▲
Si vous ne voulez charger qu'une seule ligne de la base de données, et ne pas faire l'équivalent d'un SELECT *, sachez que là encore, vous pouvez le faire. Par exemple, voyons comment nous pouvons récupérer uniquement l'enregistrement numéro 10248 de la table Orders de notre base de données :
using (new TransactionContext(TransactionOption.RequiresNew))
{
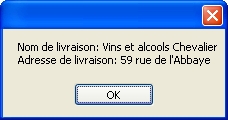
// Chargement de la commande n°10248
Order order = northwind.Orders.Fill(10248);
MessageBox.Show(
String.Format("Nom de livraison: {0}{1}Adresse de livraison: {2}", order.ShipName,
Environment.NewLine, order.ShipAddress));
}
Le résultat apparait dans une boîte de dialogue :
Pour être sûr que les résultats ne soient pas erronés, regardons dans la base de données :

Si l'on regarde la requête SQL qui a été exécutée, on s'aperçoit qu'il ne s'agit que d'un simple SELECT avec un WHERE :
SELECT A0.[OrderID], A0.[CustomerID], A0.[EmployeeID], A0.[OrderDate], A0.[RequiredDate], A0.[ShippedDate], A0.[ShipVia],
A0.[Freight], A0.[ShipName], A0.[ShipAddress],
A0.[ShipCity], A0.[ShipRegion], A0.[ShipPostalCode], A0.[ShipCountry]
FROM [Northwind].[dbo].[Orders] A0
WHERE (A0.[OrderID] = 10248)III-I. Ajouts d'enregistrements dans la base de données▲
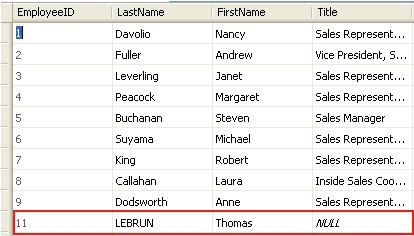
Pour ajouter des enregistrements à la base de données, rien de plus simple : il vous suffit simplement d'appeler la méthode AddNew de la table de votre modèle de persistance.
using (TransactionContext ts = new TransactionContext(TransactionOption.RequiresNew))
{
// Ajout d'une ligne dans la table Employees
northwind.Employees.AddNew("LEBRUN", "Thomas");
// On met à jour la base de données
northwind.Employees.Update();
// Validation de la transaction
ts.Commit();
}
Une fois encore, la requête SQL autogénérée par Persistent Datasets peut être visualisée :
DECLARE @scope_identity int;
INSERT INTO [Northwind].[dbo].[Employees]([LastName], [FirstName], [Title], [TitleOfCourtesy], [BirthDate], [HireDate],
[Address], [City], [Region],
[PostalCode], [Country], [HomePhone], [Extension], [Photo], [Notes], [ReportsTo], [PhotoPath])
VALUES('LEBRUN', 'Thomas', NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL);
SELECT @scope_identity = SCOPE_IDENTITY();
SELECT @scope_identity;
On voit même que Persistent Datasets est capable de déclarer des paramètres, que vous pourrez réutiliser dans votre code pour afficher, par exemple, le numéro de l'employé, etc.
III-J. Modifications d'enregistrements dans la base de données▲
Pour modifier un enregistrement, la procédure est simple :
- récupérez l'enregistrement dont vous voulez modifier une valeur ;
- appliquez les modifications que vous voulez ;
- appeler la méthode Update ;
- appelez la méthode Commit de votre transaction.
Voyons cela avec un exemple :
using (TransactionContext ts = new TransactionContext(TransactionOption.RequiresNew))
{
// Une requête sur la table Employees
EmployeeQuery query = new EmployeeQuery();
query.Criteria = query.FirstName == "Thomas" && query.LastName == "LEBRUN";
Employee [] myself = northwind.Employees.Fill(query);
myself[0].Title = "Monsieur";
myself[0].Update();
ts.Commit();
}
Vous devez maintenant (tout du moins, je l'espère), comprendre ce code : on fait une requête sur la table Employees et on récupère toutes les informations à propos de l'employé Thomas LEBRUN.
Ensuite, on modifie son titre et on met à jour la base de données (la preuve, en image) :
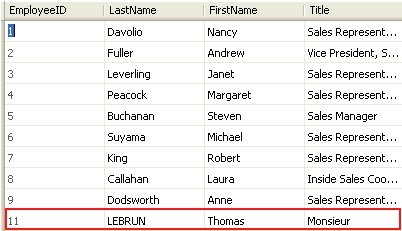
Obsevons les requêtes SQL qui ont été générées par notre couche d'abstraction :
SELECT A0.[EmployeeID], A0.[LastName], A0.[FirstName], A0.[Title], A0.[TitleOfCourtesy], A0.[BirthDate], A0.[HireDate],
A0.[Address], A0.[City], A0.[Region], A0.[PostalCode],
A0.[Country], A0.[HomePhone], A0.[Extension], A0.[Photo], A0.[Notes], A0.[ReportsTo], A0.[PhotoPath]
FROM [Northwind].[dbo].[Employees] A0
WHERE ((A0.[FirstName] = 'Thomas') AND (A0.[LastName] = 'LEBRUN'))
UPDATE [Northwind].[dbo].[Employees] SET [Title] = 'Monsieur'
WHERE [EmployeeID] = 11;
Il y a deux requêtes :
- la première sert à récupérer l'ensemble des informations de l'employé Thomas LEBRUN ;
- la deuxième sert à mettre à jour son champ Title.
Notez que Persistent Datasets sait détecter et utiliser les clés primaires, et cela sans que vous ayez besoin de faire une modification.
III-K. Suppression d'enregistrements dans la base de données▲
La suppression d'un enregistrement est très similaire à la mise à jour :
using (TransactionContext ts = new TransactionContext(TransactionOption.RequiresNew))
{
// Une requête sur la table Employees
EmployeeQuery query = new EmployeeQuery();
query.Criteria = query.FirstName == "Thomas" && query.LastName == "LEBRUN";
Employee[] myself = northwind.Employees.Fill(query);
// On marque l'élément comme bon pour supprimer
myself[0].Delete();
myself[0].Update();
ts.Commit();
}
Je ne prends pas la peine d'expliquer le code, celui-ci étant simple à comprendre. Mais n'hésitez pas à me contacter si vous avez des questions.
Jetons un rapide coup d'œil sur les requêtes SQL qui ont été générées :
SELECT A0.[EmployeeID], A0.[LastName], A0.[FirstName], A0.[Title], A0.[TitleOfCourtesy], A0.[BirthDate], A0.[HireDate],
A0.[Address], A0.[City], A0.[Region], A0.[PostalCode],
A0.[Country], A0.[HomePhone], A0.[Extension], A0.[Photo], A0.[Notes], A0.[ReportsTo], A0.[PhotoPath]
FROM [Northwind].[dbo].[Employees] A0
WHERE ((A0.[FirstName] = 'Thomas') AND (A0.[LastName] = 'LEBRUN'))
DELETE FROM [Northwind].[dbo].[Employees]
WHERE [EmployeeID] = 11;
On notera tout de même la possibilité d'effacer, d'un seul coup, toutes les lignes d'une table grâce à la méthode DeleteAll :
using (TransactionContext ts = new TransactionContext(TransactionOption.RequiresNew))
{
EmployeeQuery query = new EmployeeQuery();
northwind.Employees.Fill(query);
northwind.Employees.DeleteAll();
northwind.Employees.Update();
ts.Commit();
}IV. Conclusions▲
Tout au long de cet article, j'ai tenté de vous faire découvrir l'étendue des possibilités de Persistent Datasets. Bien entendu, je n'ai pas pu tout couvrir, tellement le produit est complexe et intéressant.
J'espère cependant qu'il aura réussi à vous séduire et à vous faire comprendre que, même si vous ne connaissez pas (ou mal) le langage SQL, vous pouvez tout de même réaliser des applications complexes et bien architecturées.
V. Liens▲
Persistent Datasets : http://www.lastcomponent.com/index.php?page=products/main&left=left
Tutoriel en ligne : http://www.lastcomponent.com/index.php?page=products/quickstart/introduction&left=products/quickstart/tree/main
Projet LINQ : http://msdn.microsoft.com/netframework/future/linq/
VI. Téléchargements▲
Le projet d'exemple : Visual Studio 2005
Version PDF de l'article : Article PDF